

ML-инженер — это развитие роли дата-сайентиста в сторону инженерной ответственности. Такой специалист не только экспериментирует с моделями машинного обучения, подбирает признаки и оценивает качество, но и думает о том, как эти модели будут жить в реальном продукте: как они внедряются, обновляются, масштабируются и не ломаются со временем. По сути, ML-инженер работает на всём пути модели — от эксперимента до продакшна — и часть этого пути реализует своими руками.
На практике это означает более широкий фокус, чем у классического исследовательского Data Science. Помимо качества модели в оффлайне, здесь важно учитывать ограничения реального окружения: скорость, стабильность, стоимость вычислений, воспроизводимость обучения и автоматизацию процессов. Поэтому ML-инженер одновременно мыслит как аналитик, как разработчик и как инженер по эксплуатации моделей. Именно такой набор навыков стал востребованным, когда машинное обучение перестало быть экспериментом и стало частью бизнес-критичных систем: рекомендаций, антифрода, поиска, медицины, рекламы. По этой причине всё больше компаний ожидают от специалистов не только умения обучить модель, но и способности довести её до надёжного и поддерживаемого решения.
В этой статье расскажу, чем отличаются специалисты ML от других профессий, каким стеком они должны обладать и где можно научиться необходимым навыкам.
Коротко о роли и чем она отличается от смежных
На практике границы между ролями в дата-командах часто размыты, особенно в небольших компаниях. При этом различия хорошо видны, если смотреть на процесс работы с данными и моделями поэтапно: от анализа и подготовки данных, через разработку моделей, к их внедрению и поддержке в продукте. Каждая роль отвечает за свой участок этого процесса и решает разные по природе задачи.
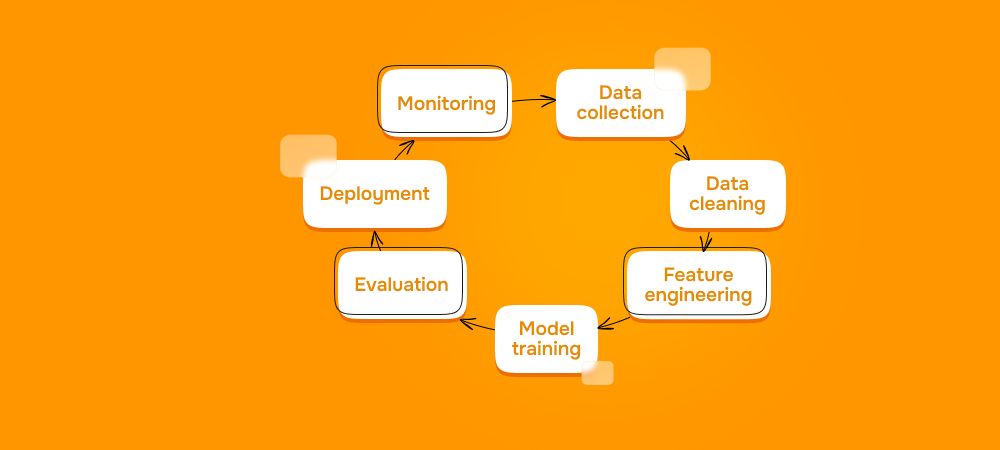
Инженер данных отвечает за первый слой — инфраструктуру данных. Он строит и поддерживает пайплайны, хранилища и фичесторы, следит за качеством данных, скоростью и надёжностью обработки. Если данные нестабильны или недоступны, аналитика и ML сразу замедляются или ломаются. Так что главная задача инженера — обеспечить доступные, воспроизводимые и готовые к использованию данные для всего последующего процесса.
Аналитик данных также работает на ранних этапах, но опирается уже на готовые данные, подготовленные дата-инженерами (собранные, очищенные и приведённые к удобному для анализа виду). Используя их, аналитик помогает лучше понять бизнес-контекст: какие процессы работают так, как ожидается, а где появляются отклонения и узкие места. Он находит устойчивые закономерности, формулирует наблюдения и гипотезы и даёт фактуру, на которую в дальнейшем могут опираться продуктовые, технические и ML-команды. Также аналитик часто закрывает быстрые ad-hoc запросы бизнеса, ответы на которые можно получить напрямую из данных.
Дата-сайентист работает на этапе разработки и проверки моделей. Он формулирует ML-задачу, подбирает признаки, алгоритмы и метрики, проводит эксперименты и сравнивает модели между собой. Основная часть работы проходит в оффлайн-режиме: анализ данных, ноутбуки, эксперименты, валидация на отложенных выборках. Цель Data Scientist — найти модель, которая действительно решает задачу лучше простых или базовых подходов. Вопросы внедрения в продукт при этом часто либо остаются вторичными, либо передаются другим ролям.
ML-инженер работает на стыке исследований и продакшна. Он умеет обучать модели и понимать метрики, но помимо этого его задача — обеспечить стабильную работу модели в продукте: чтобы она корректно обрабатывала реальные данные, быстро возвращала предсказания, обновлялась и не теряла в качестве. В отличие от дата-сайентиста, ML-инженер отвечает не только за результаты экспериментов, но и за инженерную надёжность модели в реальных условиях. Поэтому во многих компаниях, где важно быстро и безопасно внедрять ML-решения для пользователей, всё чаще ищут именно таких специалистов.
MLOps-инженер работает уже чисто на уровне платформы и процессов. Его задача — создать и поддерживать инфраструктуру, в которой можно обучать, выкатывать, мониторить и обновлять модели предсказуемо и безопасно. В их задачах нет исследовательской или экспериментальной компоненты, в основном это автоматизация обучения и деплоя, управление версиями моделей и данных, мониторинг качества и деградаций, алерты и откаты. В зрелых командах MLOps-инженер не работает с конкретной моделью, а обеспечивает среду, которой пользуются ML-инженеры и data scientists.
В итоге ML-инженер оказывается на стыке сразу нескольких этапов: он опирается на данные и выводы аналитиков, использует инфраструктуру data engineering и MLOps, но при этом самостоятельно работает с моделями и отвечает за их поведение в продукте. Именно это сочетание аналитики, машинного обучения и инженерии и отличает роль ML-инженера от остальных.
Обязанности и типичные задачи ML-инженера
Работа ML-инженера редко выглядит как непрерывное обучение моделей. В реальности это набор разноплановых направлений, связанных с тем, чтобы модель не просто хорошо работала в эксперименте, а стабильно приносила пользу в продукте. Часть из них похожа на работу дата-сайентиста, часть — на разработку и инженерию, и именно их сочетание определяет повседневную работу.
Вот примерный список задач ML-инженера, от идеи до продакшна:
- Формулирование ML-задачи с точки зрения продукта. Совместно с продуктовой командой и аналитиками он определяет, что модель должна предсказывать, по каким метрикам оцениваться и какие есть ограничения по скорости, нагрузке и стоимости вычислений.
- Подготовка данных. Вместе с инженерами данных и аналитиками он собирает, очищает и проверяет данные, готовит признаки и следит, чтобы данные в обучении и продакшне были согласованы и не «ломались» со временем.
- Обучение и оффлайн-тестирование модели. Выбор алгоритмов, настройка гиперпараметров и проверка качества на отложенных выборках.
- A/B-тестирование и валидация в продукте. Совместно с аналитиками и продуктовой командой проверяет, как новая модель ведёт себя на пользователях и влияет на метрики продукта, выбирает оптимальный вариант.
- Оптимизация модели для продакшна — уменьшение размера, ускорение работы, упрощение архитектуры, конвертация в удобные для деплоя форматы.
- Мониторинг и поддержка модели — отслеживание качества предсказаний, скорости работы и возможной деградации, настройка алертов.
- Автоматизация переобучения и релиза новых версий — совместно с MLOps-инженером и инженером данных строит пайплайны обучения и обновления модели без ручного вмешательства.
Практический момент, который часто удивляет новичков: обучение модели занимает лишь небольшую часть времени. Основная работа ML-инженера — это данные, интеграция, отладка и поддержка. В продакшне почти всегда возникают ситуации, которые невозможно увидеть в экспериментальном ноутбуке: пропущенные данные, неожиданные значения, рост нагрузки или постепенное ухудшение качества. Именно работа с такими кейсами и составляет большую часть реальной инженерной практики.
Направления в ML
Термин «машинное обучение» стал уже слишком широким, чтобы называть им специалистов напрямую. Основное различие между направлениями часто определяется типом данных, с которыми приходится работать:
- Классические табличные данные — строки и столбцы с числовыми или категориальными признаками. Сюда относятся задачи кредитного скоринга, предсказания оттока, классификации и регрессии на структурированных данных;
- NLP (Natural Language Processing) — обработка текста и естественного языка (то есть который не создан целенаправленно для машины). Такие модели анализируют сообщения, документы, отзывы, создают рекомендации, чат-ботов, генеративный текст;
- CV (Computer Vision) — работа с изображениями и видео. Классические задачи здесь — классификация, детекция объектов, сегментация, восстановление или улучшение изображений;

- Audio / Speech — обработка звуковых сигналов, распознавание речи, генерация аудио, выявление аномалий по звуку.
Для других типов информации пока не придумали способ, как их оцифровывать 🙂
Также можно выделить ещё одну отдельностоящую область ML — Reinforcement Learning (RL). В таких задачах обучение происходит через взаимодействие с окружающей средой: модель получает награды за действия и постепенно учится достигать целей, а в качестве данных используются состояния среды и действия агента. Этот приём распространён в робототехнике, играх, оптимизации процессов, и активно проникает в другие области — например, при обучении LLM в NLP.
Ещё один современный тренд — мультимодальные модели, которые умеют работать сразу с разными типами данных. Например, объединять текст, изображения и звук в одной модели, чтобы принимать решения на основе комплексной информации. Такие подходы становятся всё более востребованными в продуктовых системах, где данные одного типа не дают полной картины.
Типичный стек инструментов и навыки
Основное, что реально понадобится в первые 1–2 года:
- Язык и экосистема: Python, библиотеки — NumPy, pandas, scikit-learn, PyTorch/TensorFlow + специфические для вашего направления из пунктов выше;
- Хранение и обработка данных: SQL, Spark, S3 (зависит от технологического стека компании);
- Инфраструктура: Docker, REST, CI/CD, MLflow, AirFlow;
- Базовые науки: статистика, оптимизация, линейная алгебра, понимание ML-алгоритмов и метрик в зависимости от сферы;
- В части soft skills — инженерная дисциплина и аккуратности при работе с большими данными, умение формулировать требования, коммуникация с непрофильными коллегами.
Не обязательно знать всё идеально. Сфокусируйтесь сначала на Python, практических ML-библиотеках и принципах работы моделей в production.
И ещё один практический трюк: для резюме лучше выбрать 2–3 самых содержательных проекта (рабочих или учебных) и рассказать о них в формате SMART:
S (Specific) — конкретная цель проекта, M (Measurable) — что измерялось и какие метрики использовались, A (Achievable) — какие методы и подходы применялись, R (Relevant) — как проект связан с бизнес- или учебной задачей, T (Time-bound) — результаты, которых удалось достичь, и в какие сроки.
Такой подход гораздо эффективнее, чем перечислять десятки недокументированных экспериментов или длинный список навыков и фреймворков, с которыми вы умеете работать: конкретика и наглядные результаты всегда воспринимаются сильнее.
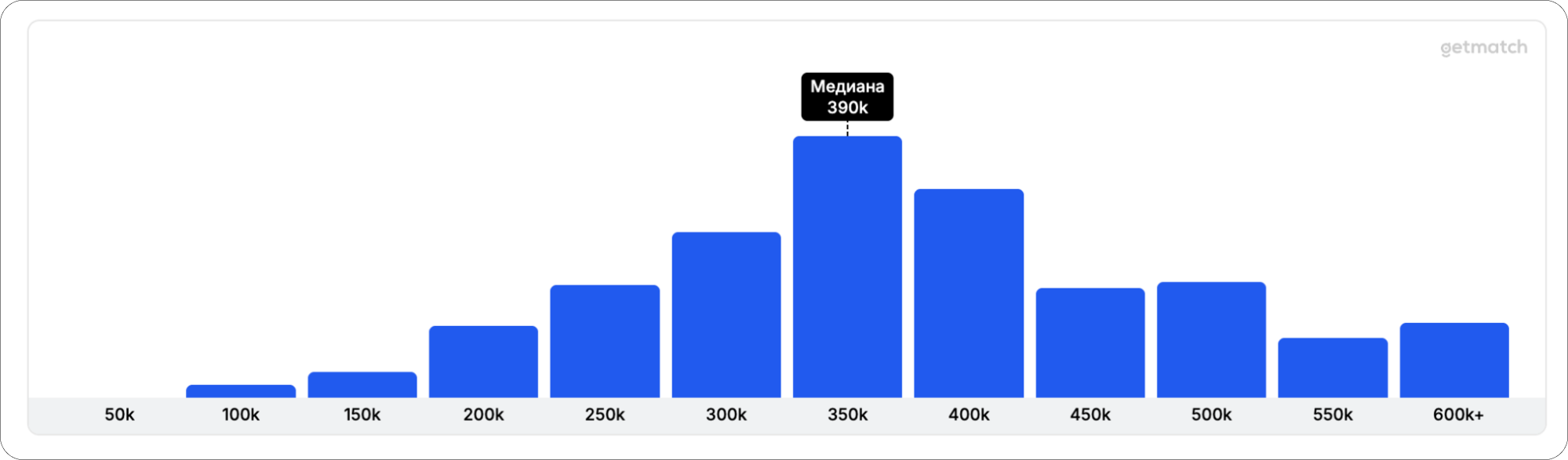
Зарплаты в 2026 году
Зарплаты сильно зависят от страны, города, уровня и компании. Посмотрим на некоторые ориентиры на 2026 год для РФ по данным getmatch.
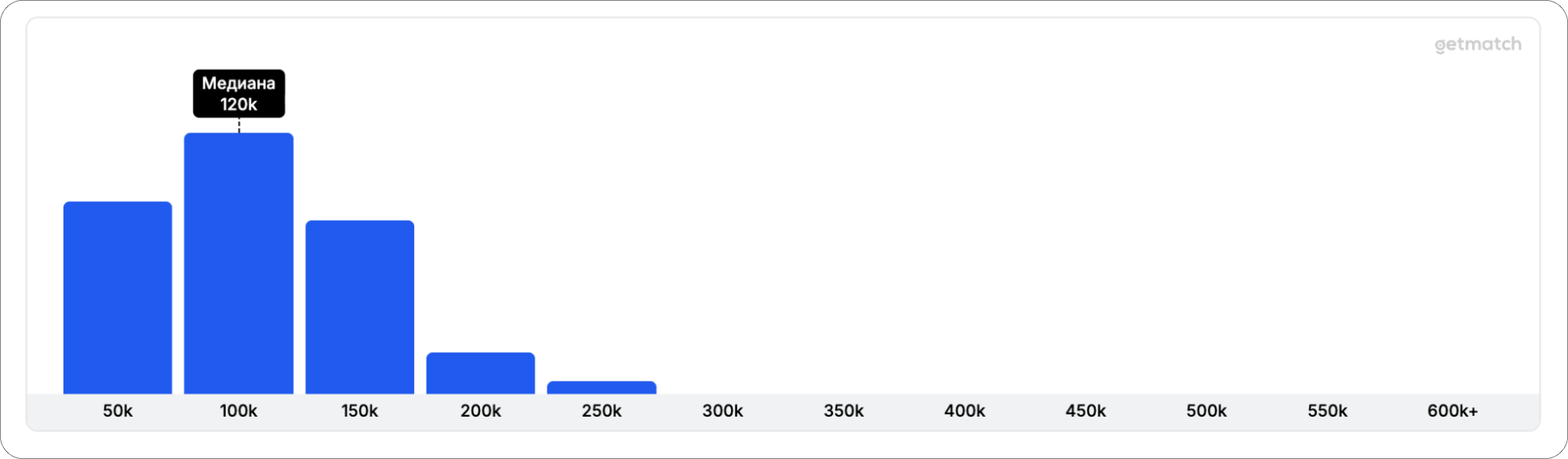
Junior
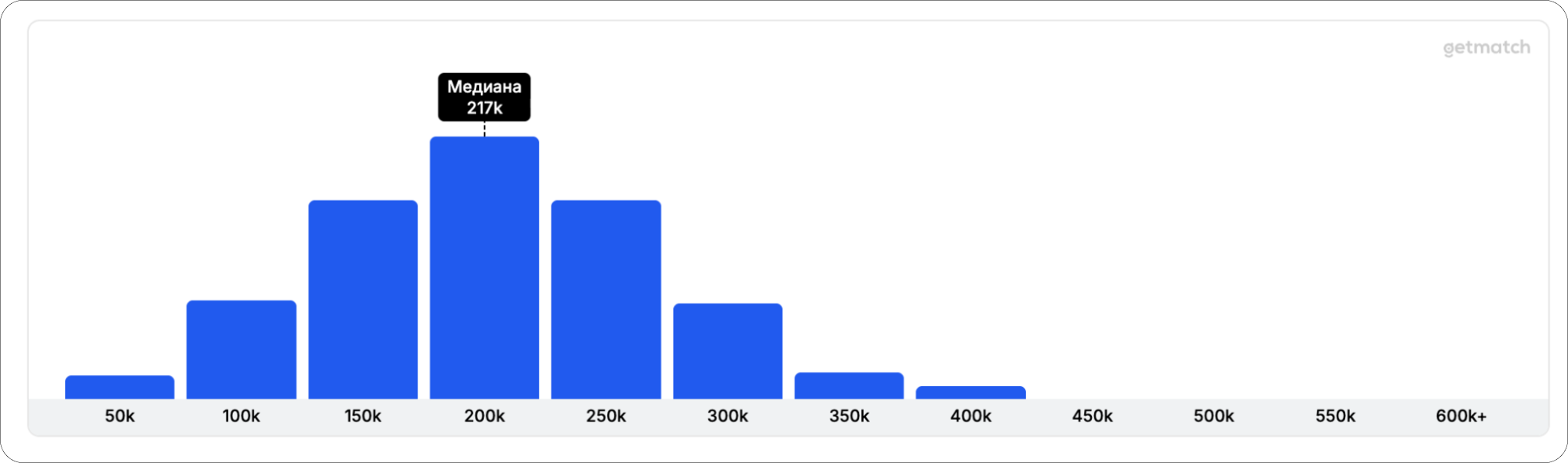
Middle
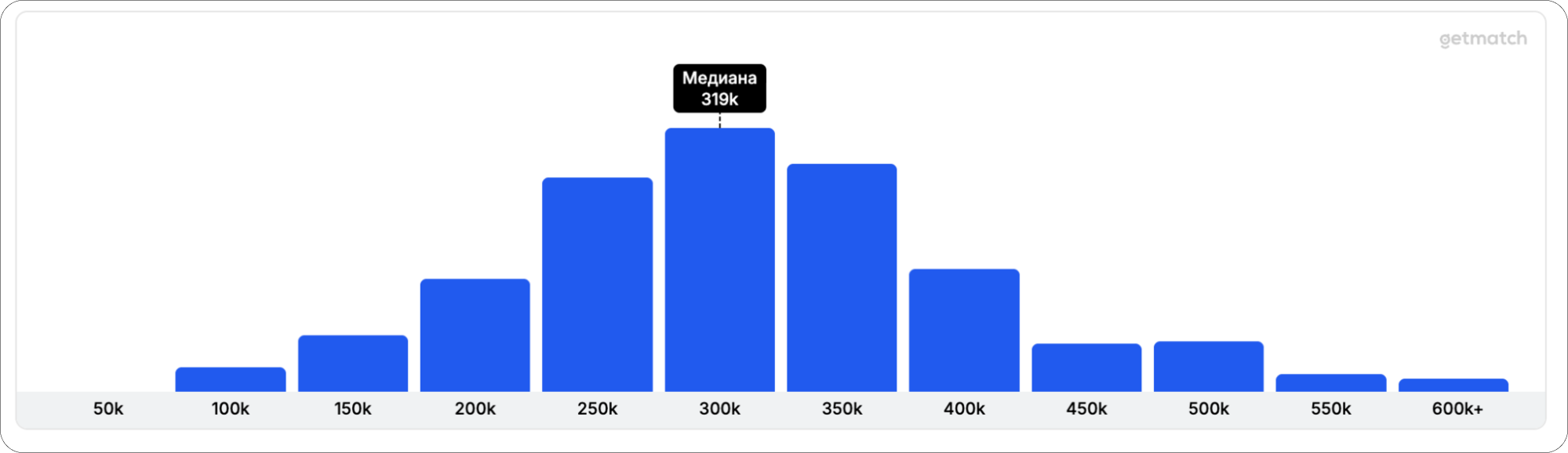
Senior
Team Lead
В США средняя типичная годовая компенсация ML-инженера находится в диапазоне примерно $128k-$201k, при этом в крупных технологических компаниях total compensation (включая акции и бонусы) часто выше — медиана по некоторым выборкам ~$240k—$300k для более высоких уровней.
Также многие senior/lead-позиции в высококонкурентных компаниях (FAANG-уровень, старшие роли в ML) имеют значительную долю компенсации в виде акций и бонусов; встречаются и экстремально высокие базовые оклады.
Тренды и навыки ML-инженеров в ближайшие годы
Профессия ML-инженера постоянно развивается: появляются новые направления, меняются инструменты и подходы к внедрению моделей в продукты. Ниже ключевые тренды, на которые стоит ориентироваться в ближайшие годы, чтобы оставаться востребованным специалистом.
- Расширение области навыков. Сегодня от ML-инженеров ожидают не только умения обучать модели, но и сопровождать их в продакшне, интегрировать с продуктами и работать в связке с MLOps, дата-инженерами и DevOps. Понимание бизнес- и предметной области также становится всё более важным.
- Автоматизация и low-code платформы. AutoML и инструменты с «минимальным кодом» снижают порог для базовых задач, но растёт спрос на специалистов, которые умеют интегрировать эти решения в продукт и контролировать границы применения.
- Рост MLOps и стандартизация процессов. Инфраструктура для развёртывания, мониторинга и обновления моделей становится критичной; рынок MLOps также продолжает быстро расти, поэтому экспертиза в production-инструментах будет становиться всё более востребованной.
- Explainability, безопасный и ответственный AI. ML-инженерам всё чаще приходится думать про аудит моделей, управление рисками и соответствие стандартам AI-trust.
- Недостаток опытных специалистов и рост стажировок — сеньоров не хватает, но растёт количество программ для начинающих, поэтому практика и опыт работы с реальными данными становятся ключевыми. И как всегда, креативность и способность придумывать нестандартные решения остаются главными помощниками в профессии.
Плюсы и минусы профессии
Плюсы:
- Высокий спрос и конкурентные зарплаты;
- Работа над интересными задачами, которые видны в продукте и дают измеримый эффект;
- Широкие возможности роста: от инженера до тимлида ML-команды или архитектуры ML-платформ;
- Большое количество доменных направлений: везде, где есть достаточно данных, можно применить ML, поэтому если интересуетесь конкретной сферой (экономика/e-commerce/медицина и т. д.) — можете найти во всех смыслах интересную для себя позицию.
Минусы:
- Высокая требовательность к самообучению — технологии и инструменты быстро меняются, нужно постоянно быть в курсе новинок, чтобы применять их у себя в работе;
- Нужно понимать, что значительная часть работы — инженерная рутина (пайплайны, деплой, отладка), а не только эксперименты и исследования;
- В продакшне часто возникают самые неожиданные проблемы, которые важно продумать заранее — для этого нужны внимательность и широкий и реалистичный взгляд на продукт, данные и работу модели.
Если вам интересно сочетание науки и инженерной практики и вы готовы к постоянному обучению и дисциплине, профессия ML-инженера идеально подойдёт. Здесь есть и творческая сторона — выбор моделей, метрик, подходов — и ощутимый результат: вы сразу видите, работает ли модель в продукте и приносит ли пользу бизнесу.