

Машинное обучение — это направление информатики, которое позволяет компьютерам обучаться на данных и делать прогнозы или классификации без явного программирования. Это позволяет находить закономерности в данных и принимать решения на основе этих закономерностей.
Основой этой области являются алгоритмы машинного обучения, которые предоставляют различные инструменты для решения задач, таких как прогнозирование непрерывных значений (регрессия), определение категорий (классификация), группировка схожих элементов (кластеризация) и многое другое.
В этой статье мы рассмотрим наиболее популярные алгоритмы машинного обучения — начиная с простых моделей, таких как линейная регрессия, и постепенно переходя к более сложным, таким как нейронные сети. Это поможет вам понять принцип работы этих механизмов и их практическое применение.
Что такое машинное обучение
Машинное обучение — это набор алгоритмов, которые позволяют компьютерам учиться на данных и выполнять задачи без явного программирования.
Существует несколько видов машинного обучения:
- Обучение с учителем (Supervised Learning). Алгоритмы этого типа обучаются на данных с известными ответами. К этому виду относятся линейная и логистическая регрессия.
- Обучение без учителя (Unsupervised Learning). Здесь алгоритмы работают с данными без чётких ответов и самостоятельно обнаруживают закономерности. К этому виду относятся методы кластеризации, например, K-Means.
- Обучение с подкреплением (Reinforcement Learning). В этом случае алгоритмы учатся, взаимодействуя с окружающей средой и получая награды или штрафы за свои действия.
Типы ML-алгоритмов
Линейная регрессия (Linear Regression)
Линейная регрессия — один из фундаментальных способов предсказания непрерывных значений. Она моделирует взаимосвязь между величинами. Применяется для простого исследования и предсказания линейной зависимости.
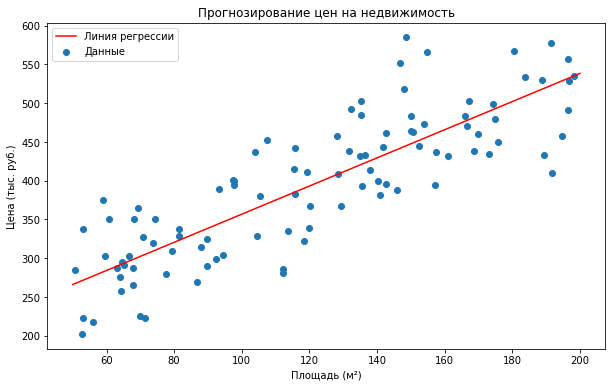
Пример линейной регрессии — прогнозирование стоимости недвижимости в зависимости от размера и расположения объекта. Модель, учитывающая эти факторы и предсказывающая цену объекта, может быть построена с использованием линейной регрессии.
- Плюсы: лёгкость реализации и понимания, быстрое освоение.
- Минусы: не подходит для сложных взаимосвязей.
Пример использования линейной регрессии:
Линейный дискриминантный анализ (Linear Discriminant Analysis)
Метод LDA (Linear Discriminant Analysis) ищет комбинации показателей, лучше всего разделяющие классы. Он используется с целью сокращения размерности данных. LDA эффективен в случае, когда необходимо сократить количество признаков, не теряя информацию, которая важна для разделения на группы.
Пример использования — классификация изображений по категориям. LDA способен снизить размерность данных и улучшить классификацию.
- Плюсы: хорошо снижает размерность данных, легко реализуется.
- Минусы: не учитывает нелинейные границы разделения категорий.
Как построить?
- Соберите набор данных с метками классов.
- Применяйте матрицы дисперсии для поиска оптимальных линейных комбинаций признаков.
- Обучите модель на данных, чтобы найти оптимальные коэффициенты.
Логистическая регрессия (Logistic Regression)
Логистическая регрессия (Logistic Regression) — метод, который используется для разделения данных на два класса. Он позволяет моделировать вероятность отнесения к одному из двух возможных вариантов. Применяется в случаях, когда необходимо предсказать вероятность возникновения определённого события.
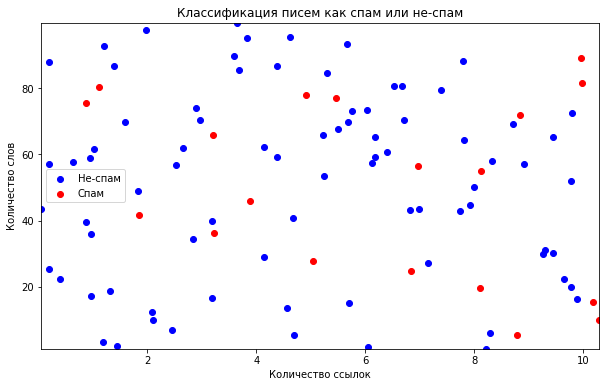
Пример использования — классификация спама и не-спама в электронной почте. Логистическая регрессия может предсказать вероятность того, что письмо является спамом.
- Плюсы: проста в реализации и интерпретации, подходит для бинарной классификации.
- Минусы: не подходит для многоклассовой классификации.
Пример классификации электронных писем на основе двух признаков — количества ссылок и количества слов в письме:
Алгоритм построения дерева решений (Decision Tree)
Алгоритмы построения дерева решений (Decision Tree) используются для задач классификации или регрессии. Эти алгоритмы особенно актуальны, когда важно понять, как те или иные параметры влияют на прогноз.
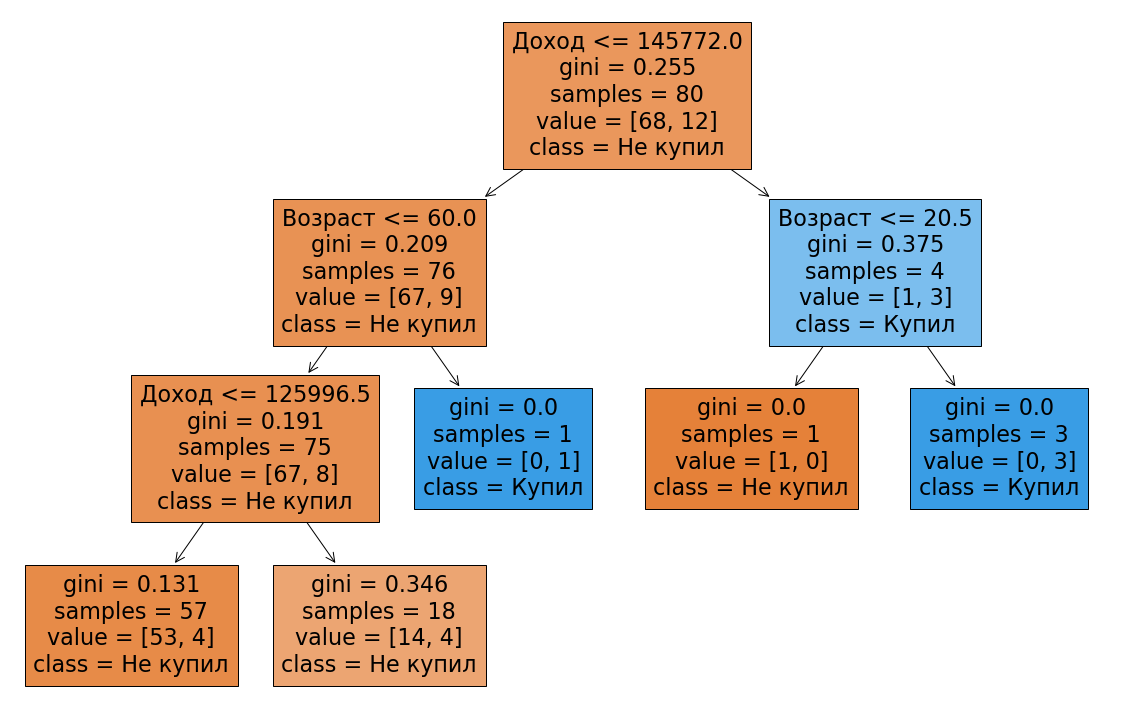
Например, прогнозирование вероятности покупки продукта на основе демографических данных. Дерево решений может помочь понять, какие признаки наиболее важны для принятия решения.
- Плюсы: просты в интерпретации и реализации, могут обрабатывать как числовые, так и категориальные признаки.
- Минус: может переобучаться на данных.
Пример использования дерева решений:
Как построить?
- Соберите набор данных с признаками и целевым значением.
- Постройте дерево, разбивая данные на подмножества на основе признаков.
- Обучите модель на данных, чтобы найти оптимальные разбиения.
Метод К-ближайших соседей (K-Nearest Neighbors)
Это алгоритм, который классифицирует объекты на основе их сходства с соседями по параметрам. Он отличается простотой и точностью при работе с небольшими массивами информации. Его также используют для задач классификации или регрессии.
Пример использования — рекомендация продуктов на основе предпочтений похожих пользователей. KNN может помочь найти похожих пользователей и предложить им продукты.
- Плюсы: прост в реализации и понимании, может обрабатывать как классификацию, так и регрессию.
- Минус: медленный на больших наборах данных.
Как построить?
- Соберите набор данных с метками классов.
- Используйте расстояние (например, евклидово) для нахождения ближайших соседей.
- Не требуется явного обучения, но необходимо выбрать оптимальное значение кластеров.
Метод K-средних (K-Means Clustering)
K-Means Clustering — метод разбиения совокупности объектов на заданное число групп по определённым критериям. Он широко применяется при анализе массива информации. Эффективен для определения групп схожих объектов.
Пример использования — разделение клиентов на группы в зависимости от их поведения. K-средних может помочь разделить клиентов на группы с похожим поведением.
- Плюсы: легко понять, как работает алгоритм, помогает находить закономерности.
- Минус: не применим к кластерам произвольной формы.
Как построить?
- Соберите набор данных без меток классов.
- Инициализируйте центры кластеров и итеративно обновляйте их, чтобы минимизировать расстояние между объектами и центрами.
- Не требуется явного обучения, но необходимо выбрать оптимальное значение K.
Апостериорная (иерархическая) кластеризация (Hierarchical Clustering)
Это метод, который создаёт систему вложенных друг в друга групп. Он даёт возможность гибко регулировать уровень детализации и особенно удобен для обнаружения сложных паттернов в данных.
Пример использования: исследование генетических последовательностей для выявления родственных связей. Апостериорная классификация может помочь построить иерархию родственных связей.
- Плюсы: позволяет гибко выбирать уровень детализации, эффективен при выявлении структур сложной формы.
- Минус: может быть медленным при работе с большими массивами данных.
Как построить?
- Соберите набор данных без меток классов.
- Используйте матрицу расстояний для построения иерархии кластеров.
- Не требуется явного обучения, но необходимо выбрать уровень детализации.
Сигмоида (Sigmoid Function)
Сигмоида — это функция, которая преобразует сумму произведений характеристик в вероятность. Используется для определения вероятности наступления события.
Пример использования: классификация спама и не-спама в электронной почте. Сигмоида способна преобразовать сумму произведений признаков в шанс того, что сообщение является нежелательным.
- Плюсы: преобразует любое значение в вероятность, проста в реализации.
- Минус: может быть чувствительной к выбору начальных параметров.
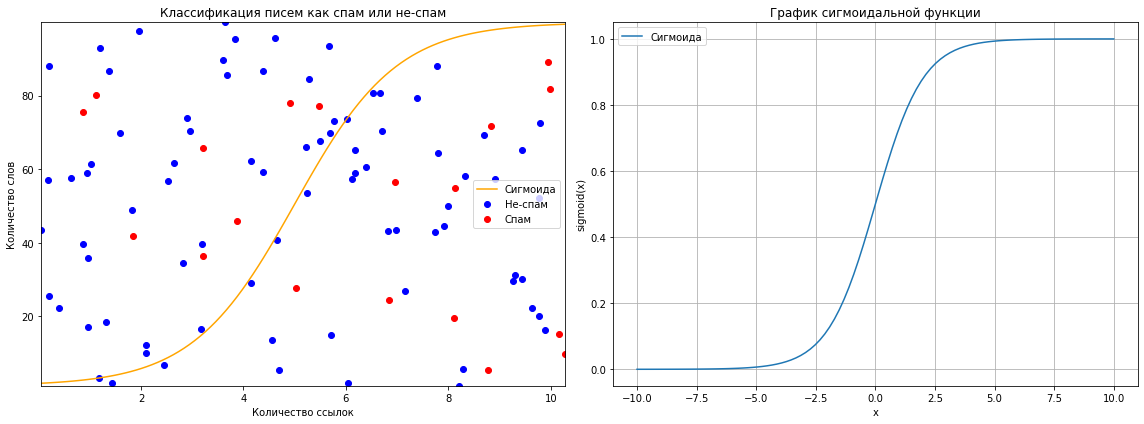
Как построить? Используйте формулу σ(x)= 11 + e-x. Часто используется в логистической регрессии.
Сети векторного квантования (Learning Vector Quantization)
LVQ — это сочетание преимуществ KNN и нейронных сетей. Он использует набор кодовых векторов для представления информации и предсказания классов.
Используется, например, для классификации изображений по категориям. LVQ способен улучшить качество классификации благодаря использованию кодовых векторов.
- Плюсы: эффективен в классификации и способен работать со сложными массивами информации.
- Минус: реализация может быть сложной.
Как построить?
- Соберите набор данных с метками классов.
- Используйте набор кодовых векторов для представления данных.
- Обновляйте кодовые векторы на основе ошибок классификации.
Метод опорных векторов (Support Vector Machines)
SVM — это мощный классификатор, который разделяет классы гиперплоскостью. SVM позволяет разделять объекты высокой размерности и может использовать ядра для нелинейной классификации.
Пример использования — классификация текстов по категориям. SVM помогает найти оптимальную границу между классами в пространстве признаков.
- Плюсы: эффективен для высокоразмерных данных и способен обрабатывать нелинейные границы классов.
- Минус: может работать медленно на больших наборах данных.
Пример использования SVM для классификации данных:
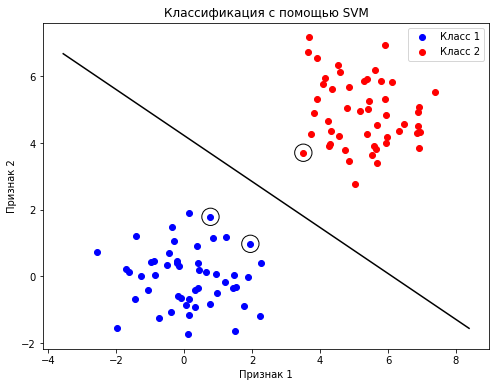
Как построить?
- Соберите набор данных с метками классов.
- Используйте ядра для нелинейной классификации.
- Обучите модель на данных, чтобы найти оптимальные веса.
Метод случайного леса (Random Forest)
Это алгоритм, который объединяет несколько решений для повышения точности и стабильности прогнозов. Он широко применяется как для задач классификации, так и для регрессии.
Например, прогнозирование вероятности дефолта по кредитным показателям. Random Forest помогает повысить точность предсказаний за счёт объединения нескольких решений.
- Плюсы: обеспечивает точность и стабильность, может работать как с классификацией, так и с регрессией.
- Минус: требует внимательного анализа для понимания результата.
Как построить?
- Соберите данные с признаками и целевым значением.
- Постройте множество деревьев на основе выборки признаков.
- Объедините прогнозы разных деревьев, чтобы получить финальный ответ.
Бэггинг
Это способ объединить множество моделей для уменьшения дисперсии предсказаний. Часто используется с древовидными моделями решений для повышения стабильности моделей.
Пример использования: прогнозирование цен на акции. Бэггинг может помочь уменьшить влияние случайных колебаний на прогнозы.
- Плюсы: уменьшает переобучение, повышает стабильность моделей.
- Минус: Может быть медленным при работе с большими массивами информации.
Как построить?
- Соберите массив с признаками и целевым значением.
- Постройте различные варианты на подвыборках массива.
- Объедините результаты, полученные каждой моделью, для получения финального итога.
Чем различается случайный лес и бэггинг деревьев
Это два метода обучения, которые используют деревья решений как базовые модели. Основные различия между ними заключаются в том, как они вводят случайность и обрабатывают признаки.
- Метод и обработка данных. Бэггинг создаёт несколько бутстрэп-выборок из исходных данных с заменой и обучает на них деревья решений. Случайный лес также использует бутстрэп-выборки, но дополнительно вводит случайность при выборе признаков для каждого дерева, что уменьшает корреляцию между деревьями и помогает избежать переобучения.
- Обработка признаков. В бэггинге все признаки используются для построения каждого дерева решений. В случайном лесе, напротив, при построении каждого дерева случайным образом выбирается подмножество признаков (обычно M для классификации, где M — общее количество признаков).
- Прогнозирование и стабильность. Оба метода агрегируют прогнозы деревьев, но благодаря случайному подбору признаков, случайный лес обеспечивает более стабильные и точные результаты, будучи менее подверженным переобучению по сравнению с бэггингом.
В итоге, случайный лес отличается от бэггинга деревьев введением дополнительной случайности при выборе признаков, что делает его более устойчивым к переобучению и позволяет получать более точные прогнозы.
Бустинг
Бустинг — это алгоритм, который формирует модели последовательно, чтобы исправить ошибки предыдущих моделей. Он особенно эффективен для задач классификации и регрессии.
Пример использования — прогнозирование вероятности покупки продукта. Бустинг может помочь улучшить точность прогнозов за счёт последовательного исправления ошибок.
- Плюсы: высокая точность и гибкость, может обрабатывать сложные данные.
- Минус: может быть сложным в реализации.
Как построить?
- Соберите набор данных с признаками и целевым значением.
- Постройте последовательность моделей, каждая из которых учитывает ошибки предыдущей.
- Объедините прогнозы моделей для получения финального результата.
Адаптивный бустинг (AdaBoost)
Это бустинг, который использует веса каждого дерева, чтобы сосредоточиться на ошибках предыдущих моделей. Он легко реализуется и эффективен для задач классификации.
Пример использования — классификация изображений по категориям. AdaBoost может помочь улучшить качество классификации за счёт использования весов ошибок.
- Плюсы: высокая точность и простота реализации, может обрабатывать как классификацию, так и регрессию.
- Минус: может переобучаться на данных.
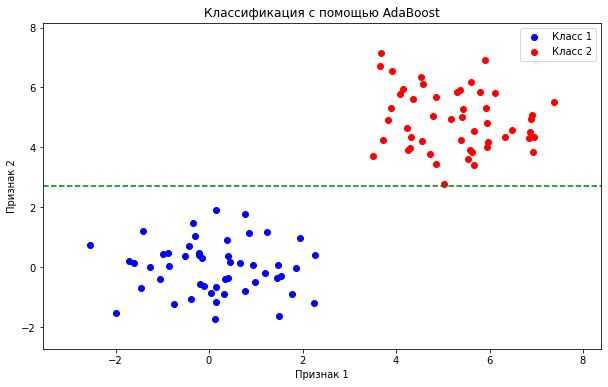
Градиентный бустинг (Gradient Boost)
Градиентный бустинг — более современный бустинговый алгоритм, использующий градиентный спуск для оптимизации функции потерь. Он широко применяется в задачах регрессии и классификации.
Пример использования: предсказание стоимости ценных бумаг. Градиентный бустинг использует градиентный спуск для повышения точности прогнозов.
- Плюсы: высокая точность, гибкость, возможность обработки сложных данных.
- Минус: требует значительных усилий при реализации.
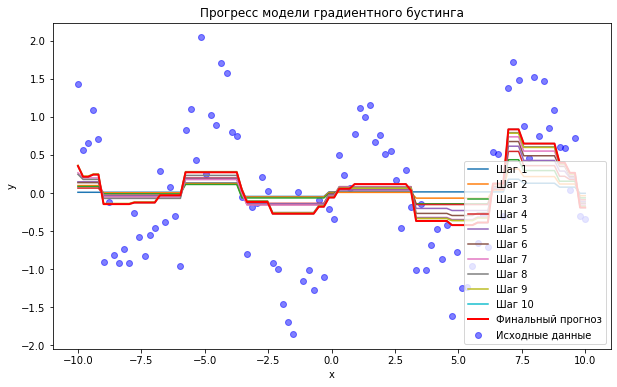
XGBoost
XGBoost — градиентный бустинг, оптимизированный по производительности и параллелизму. Он широко используется в соревнованиях по машинному обучению.
Пример использования — прогнозирование возможности неисполнения обязательств по кредитным сведениям. XGBoost способен увеличить точность прогнозов за счёт параллелизации вычислений.
- Плюсы: производительность и точность, обрабатывает большие объёмы информации.
- Минус: настройка гиперпараметров может вызвать сложности.
Наивный байесовский классификатор
Байесовский классификатор — это простой и эффективный метод, основанный на теореме Байеса для определения принадлежности объекта к какому-либо классу. Он предполагает независимость признаков, что часто не соответствует реальности, но всё равно может быть эффективным.
Пример использования: фильтрация нежелательной почты. Наивный байесовский классификатор поможет предсказать, является ли сообщение спамом.
- Плюсы: прост в реализации и интерпретации, легко усваивается.
- Минус: предполагает независимость признаков, что часто не соответствует реальности.
Визуализация результатов наивного байесовского классификатора:
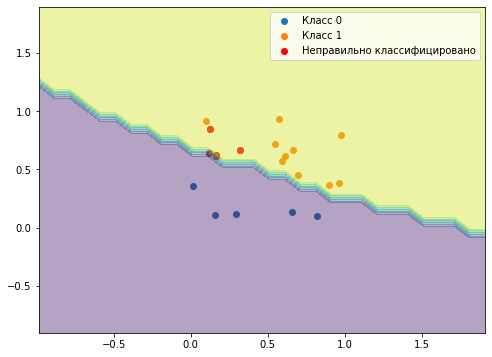
Как построить?
- Соберите данные с метками классов.
- Оцените вероятности каждого класса, используя теорему Байеса.
- Не требуется явного обучения, но важно оценить вероятности.
Алгоритм нейронных сетей
Нейросети представляют собой сложные алгоритмы, которые имитируют работу головного мозга. Они способны решать задачи классификации, регрессии и кластеризации, а также используются в глубоком обучении для обработки изображений и текстов. Нейросети помогают повысить точность распознавания благодаря сложным структурам информации.
Пример использования — распознавание лиц на фотографиях. Нейронные сети могут помочь улучшить точность распознавания за счёт использования сложных структур данных.
- Плюсы: высокая точность и гибкость, может обрабатывать сложные данные.
- Минус: может быть сложным в реализации и интерпретации.
Как построить?
- Соберите набор данных с признаками и целевым значением.
- Постройте сеть из слоев нейронов с использованием активационных функций.
- Обучите сеть на данных с помощью градиентного спуска.
Алгоритмы машинного обучения представляют собой мощные инструменты для анализа и прогнозирования данных. От простых моделей, таких как линейная и логистическая регрессия, до более сложных, таких как нейронные сети и бустинговые алгоритмы, каждый из них обладает уникальными характеристиками и сферами применения, что делает их незаменимым инструментом в современной аналитике данных. Понимание этих алгоритмов и умение их применять является ключом к успешному решению задач в области машинного обучения.